libc++源码分析之new和delete
示例:new/delete 一个对象
代码
1 | int main(int argc, char** argv) { |
汇编
1 | 0x108852450 <+0>: pushq %rbp |
1 | int main(int argc, char** argv) { |
1 | 0x108852450 <+0>: pushq %rbp |
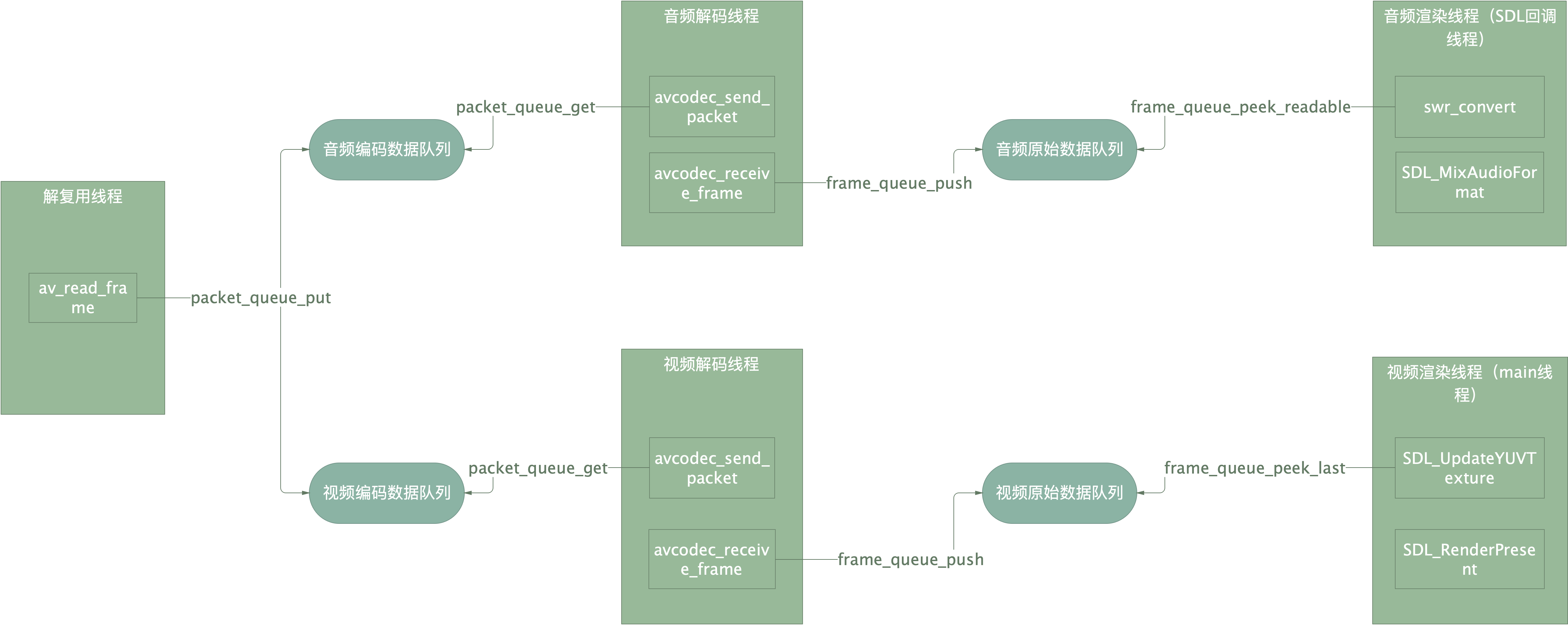
不断从Packet队列中取出一帧数据进行解码,然后将解码数据放入到Frame队列中。
1 | for (;;) { |
由主线程创建,负责媒体文件的解复用和读取,读取的数据根据流类型放入到对应的编码数据队列中
1 |
|
图像的显示最终都是由显示器完成的,显示器通过接收到的颜色矩阵来进行对应的显示。而颜色矩阵的产生一般有两种,一种是通过GPU来进行渲染生成,另一种是通过CPU来进行渲染生成。其中GPU比较适合来处理这件事情,所以其效率高。(硬件加速也就是指使用GPU来进行渲染加速)
在Android平台上,GPU渲染的API有两套,一套就是OpenGL-ES,另一套就是7.0后推出的Vulkan。目前使用最多的还是OpenGL-ES。
SDL是一个跨平台的音视频渲染库,是支持Android平台的,所以可以直接使用SDL库进行音频的播放。
但是SDL库在Android平台上的实现只有一种,就是通过JNI来调用Java层的AudioTrack来进行播放。所以如果你有其它的需求不想使用SDL库,那么可以直接使用Android平台原生API来播放音频。
前面录制的时候讲过,Android上音频输出的API比较繁琐,有多套实现。有Java层的实现AudioTrack,也有native层实现OpenSLES,在 Android O上又推出了新的native层实现AAudio,并且提供了Oboe库,对OpenSLES和AAudio进行了封装。
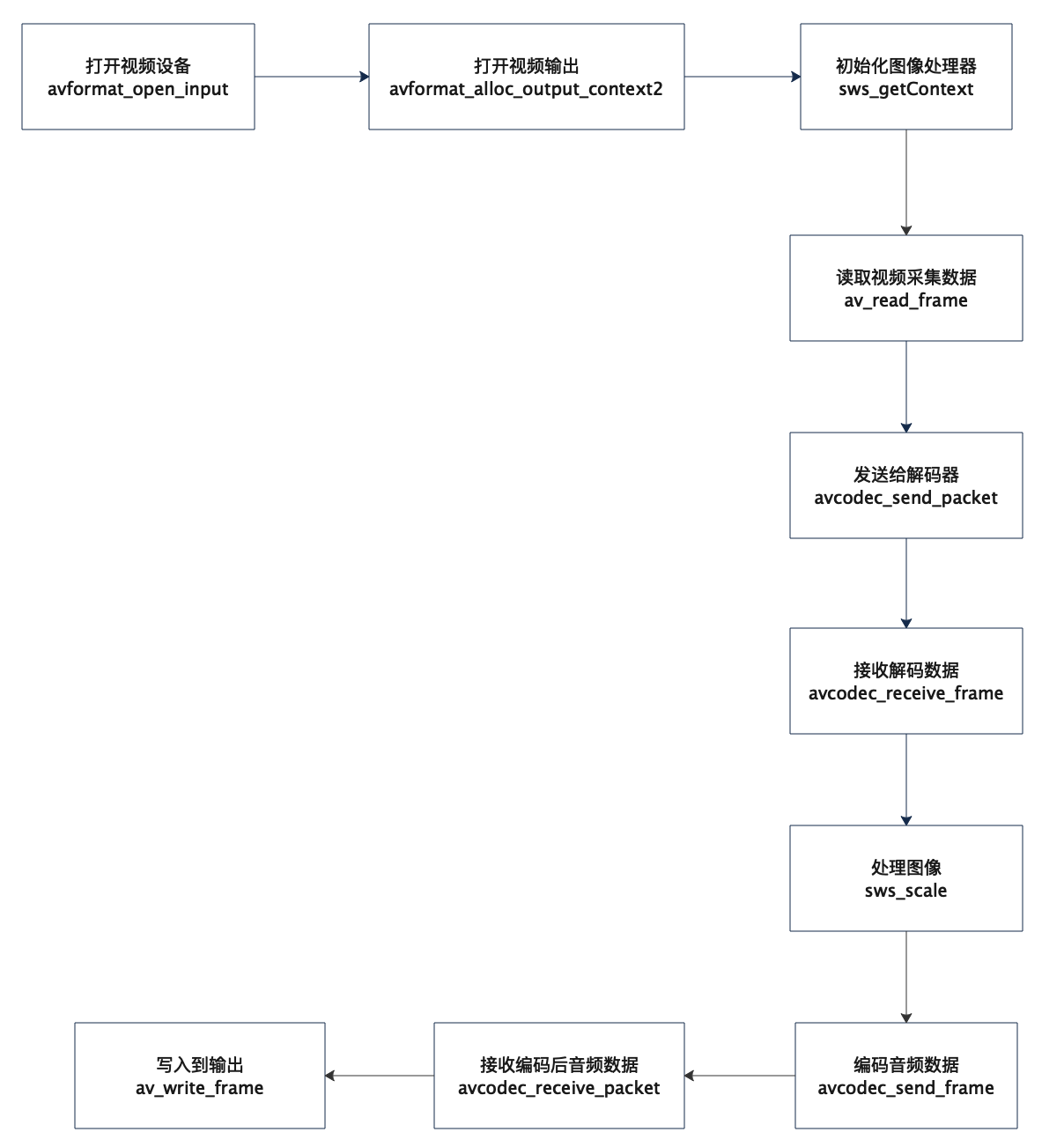
FFmpeg对于Android平台的视频输入设备API有一定的支持,但是比较局限,只支持Android N以上的版本,低版本无法使用。
其原因是因为FFmpeg采用的是Android N推出的native层camera API来实现的(NDK中的libcamera2ndk.so),而并非采用JNI的方式来调用Java层camera API。
对于视频录制API,Android平台上有两套API实现,一套是老版的Camera1,另一套是Android L之后推出的Camera2。
Camera1使用起来较为简单,但是功能相对较少,不支持多纹理输出。Camera2的API功能上虽然更加强大,但是API设计的非常底层化,不利于理解,并且YUV_420_888的数据格式,国内各大产商在实现上留下的坑太多。
Jetpack组件中,Google推出了全新的CameraX组件,对Camera1和Camera2进行了统一的封装,使得API更加简单易用。
由于FFmpeg一直都没有支持Android平台的音频输入设备API,所以无法使用FFmpeg在Android上录制音频。
Android上音频输入的API比较繁琐,有多套实现。有Java层的实现AudioRecord,也有native层实现OpenSLES,在 Android O之后又推出了新的native层实现AAudio,并且提供了Oboe库,对OpenSLES和AAudio进行了封装。
下面来详细的介绍下每套API的使用
AudioRecord是Android平台提供的录制音频的Java层API,使用起来非常简单。通过设置采集参数就可以创建一个AudioRecord对象,调用了start方法后,就可以开始读取数据了,通过read方法将数据读取到指定的缓冲区中,调用stop后就停止采集。